
NeurIPS 2021
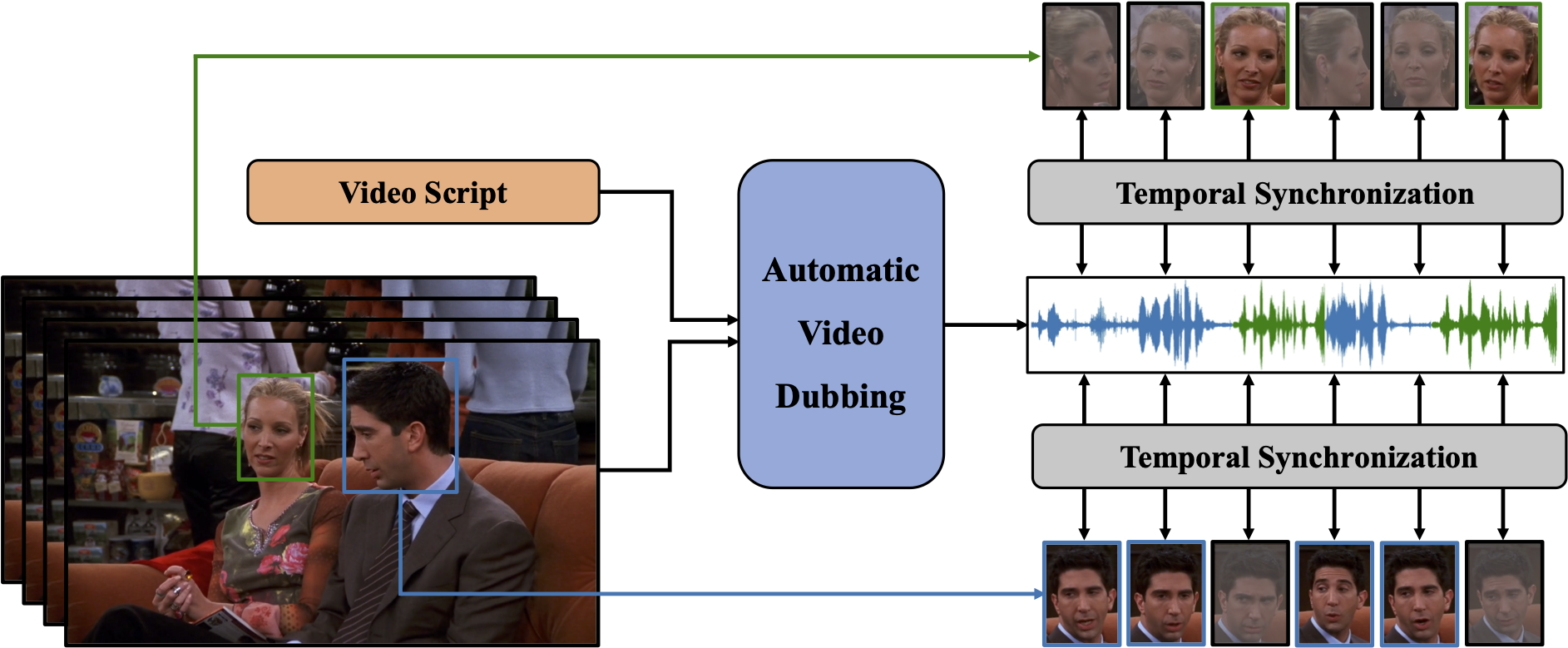
We conduct qualitative and quantitative evaluation on the chem single-speaker dataset, to compare the audio quality and the audio-visual synchronization of the video clips generated by Neural Dubber with other systems.
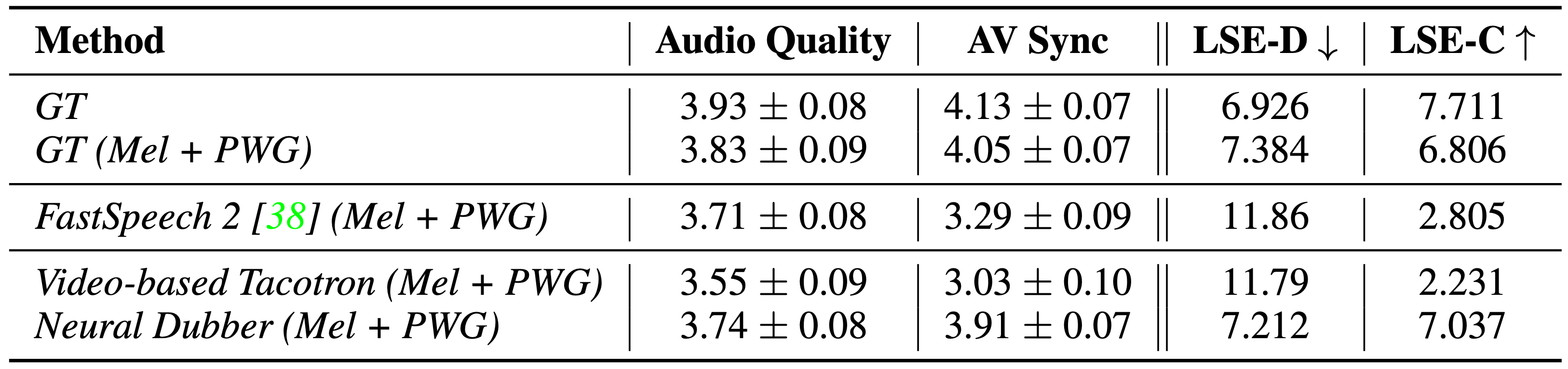
It can be seen that Neural Dubber can surpass the Video-based Tacotron baseline and is on par with FastSpeech 2 in terms of audio quality, which demonstrates that Neural Dubber can synthesize high-quality speech. Furthermore, in terms of the av sync, Neural Dubber outperforms FastSpeech 2 and Video-based Tacotron by a big margin and matches GT (Mel + PWG) system in both qualitative and quantitative evaluations, which shows that Neural Dubber can control the prosody of speech and generate speech synchronized with the video.
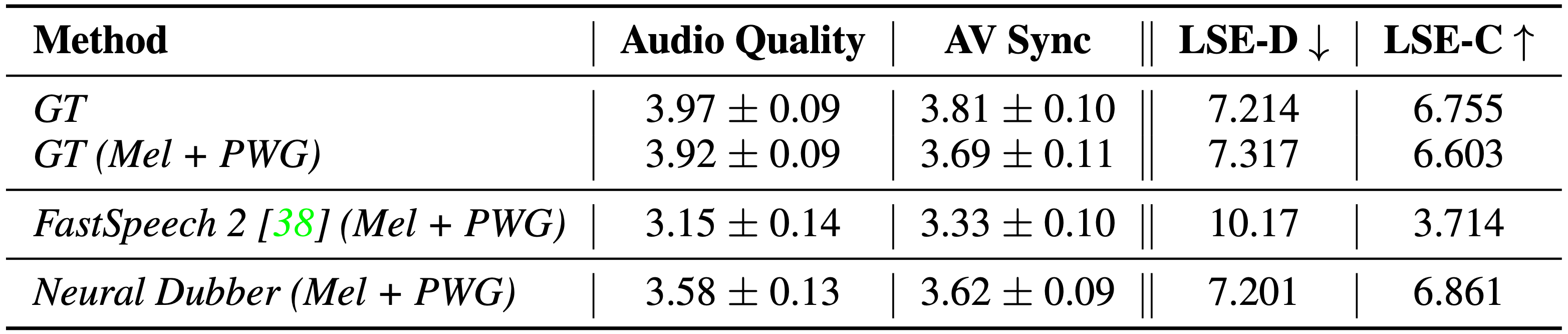
We conduct human evaluation and quantitative evaluation on the LRS2 multi-speaker dataset to compare Neural Dubber with other systems in multi-speaker setting.
| And we expect that we'll have an increase in that vapor intensity. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| Well let's just calculate from the ideal gas law. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| So I can figure out the fraction of oxygen particles from the relationship between the pressures. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| So green is plus, green is plus, these are two wave functions coming together that have positive sign everywhere. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| So now if I know the pressure goes down by about half an atmosphere, well, the total pressure used to be 2.9. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| Just 100 thousandth of a mole dissolves in about a liter of water. | ||
| GT | GT (Mel + PWG) | FastSpeech 2 |
| Video-based Tacotron | Neural Dubber | |
| WHO KNEW THAT ONE MAN | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
| THAT'S THE BEST KIND OF TEACHING | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
| THE VERY BEST TALENTS | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
| THE FIRST AND SECOND FLOOR FLATS | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
| TIME NOW FOR ONE OF THE GREATEST TV COMEBACKS OF OUR TIME | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
| YOU HAVE A PROBLEM WITH IT | |||
|
GT |
GT (Mel+PWG) |
FastSpeech 2 |
Neural Dubber |
If you find our work useful in your research, please consider citing:
@inproceedings{hu2021neural,
title={Neural Dubber: Dubbing for Videos According to Scripts},
author={Hu, Chenxu and Tian, Qiao and Li, Tingle and Yuping, Wang and Wang, Yuxuan and Zhao, Hang},
booktitle={Thirty-Fifth Conference on Neural Information Processing Systems},
year={2021}
}