1MIT,
2Toyota Research Institute,
3CMU,
4Li Auto,
5Tsinghua University
Conference on Robot Learning (CoRL 2021)
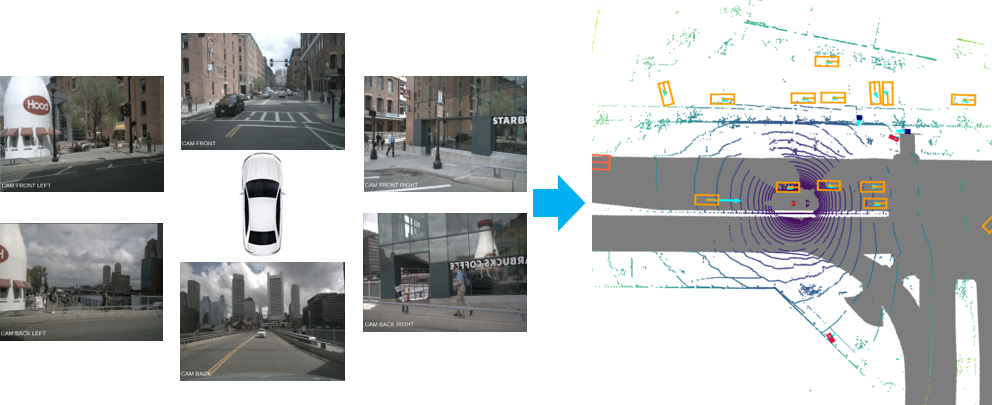
A multi-camera 3D object detection framework that does NOT require dense depth prediction or post-processing.
Abstract
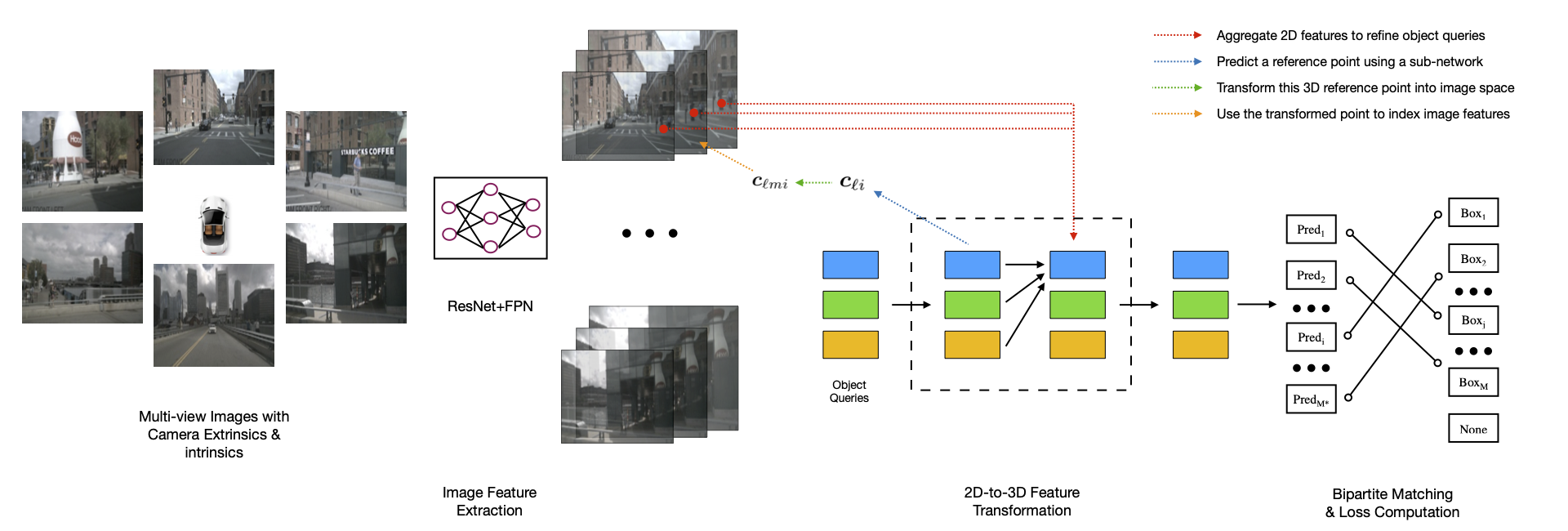
We introduce a framework for multi-camera 3D object detection. In contrast to existing works, which estimate 3D bounding boxes directly from monocular images or use depth prediction networks to generate input for 3D object detection from 2D information, our method manipulates predictions directly in 3D space. Our architecture extracts 2D features from multiple camera images and then uses a sparse set of 3D object queries to index into these 2D features, linking 3D positions to multi-view images using camera transformation matrices. Finally, our model makes a bounding box prediction per object query, using a set-to-set loss to measure the discrepancy between the ground-truth and the prediction. This top-down approach outperforms its bottom-up counterpart in which object bounding box prediction follows per-pixel depth estimation, since it does not suffer from the compounding error introduced by a depth prediction model. Moreover, our method does not require post-processing such as non-maximum suppression, dramatically improving inference speed. We achieve state-of-the-art performance on the nuScenes autonomous driving benchmark.
Method
A multi-camera 3D object detection framework. DETR3D extracts image features with a 2D backbone, followed by a set of queries defined in 3D space to correlate 2D observations and 3D predictions. Finally, a set-to-set loss is used to remove the necessity of post-processing such as non-maximum suppresion.
- 3D aware. We incorporate 3D information into intermediate computations within our architecture, rather than performing purely 2D computations in the image plane.
- Sparse. We do not estimate dense 3D scene geometry, avoiding associated reconstruction errors.
- Post-processing free. We avoid post-processing steps such as NMS.
If you find our work useful in your research, please cite our paper:
@inproceedings{
detr3d,
title={DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries},
author={Wang, Yue and Guizilini, Vitor and Zhang, Tianyuan and Wang, Yilun and Zhao, Hang and and Solomon, Justin M.},
booktitle={The Conference on Robot Learning ({CoRL})},
year={2021}
}