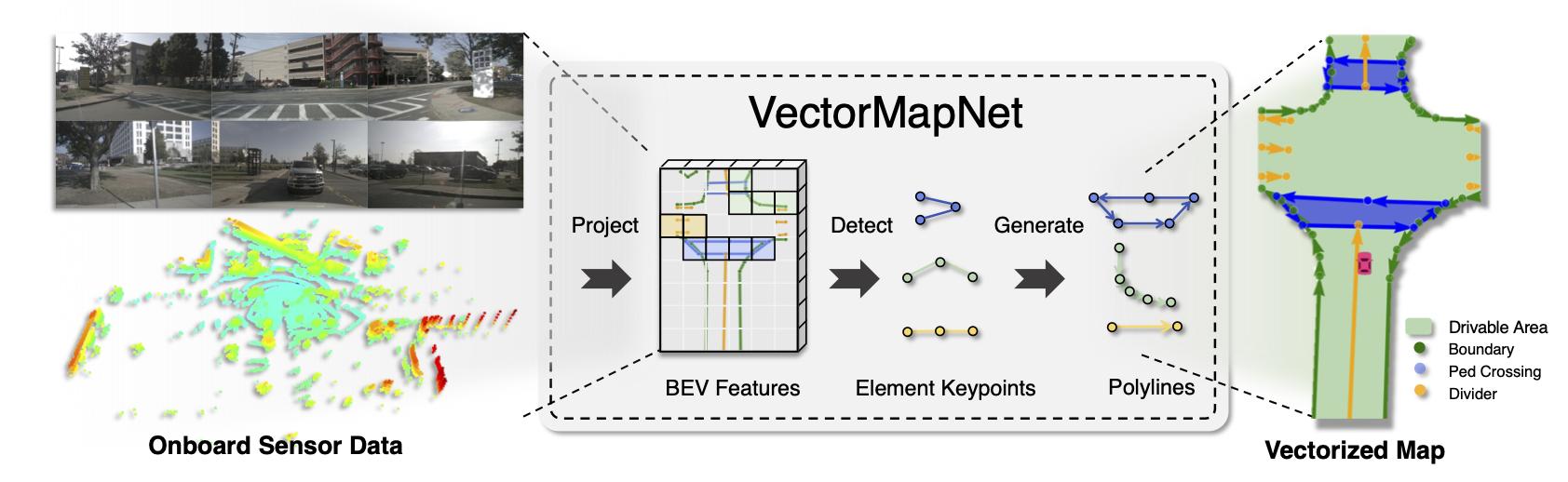
An end-to-end map learning framework that generates vectorized HD map from onboard sensor data.
To the best of our knowledge, VectorMapNet is the first work designed towards end-to-end vectorized HD map learning problems.
Motivation
Most recent HD map learning methods use dense primitives (e.g., pixels) to model maps. But learning these dense primitives complicates the pipeline and restricts the model's scalability and performance. In VectorMapNet, we represent map elements as a set of polylines that are easily linked to downstream tasks (e.g., motion forecasting), and model these polylines with a set prediction framework. The overview of our idea is presented in the Figure above.
Method
Our task is to model map elements in the urban environments in a vectorized form using data from onboard sensors, e.g., RGB cameras and/or LiDARs. These map elements include but are not limited to road boundaries, lane dividers, and pedestrian crossings, which are critical for autonomous driving.
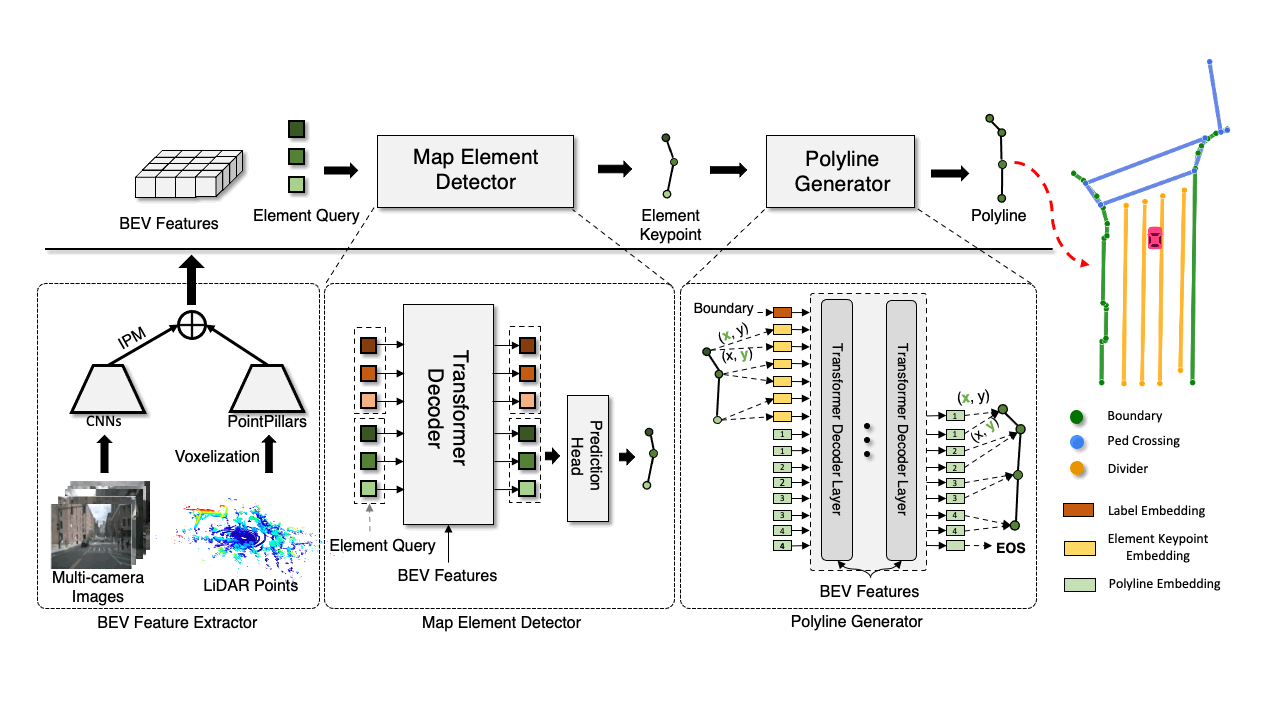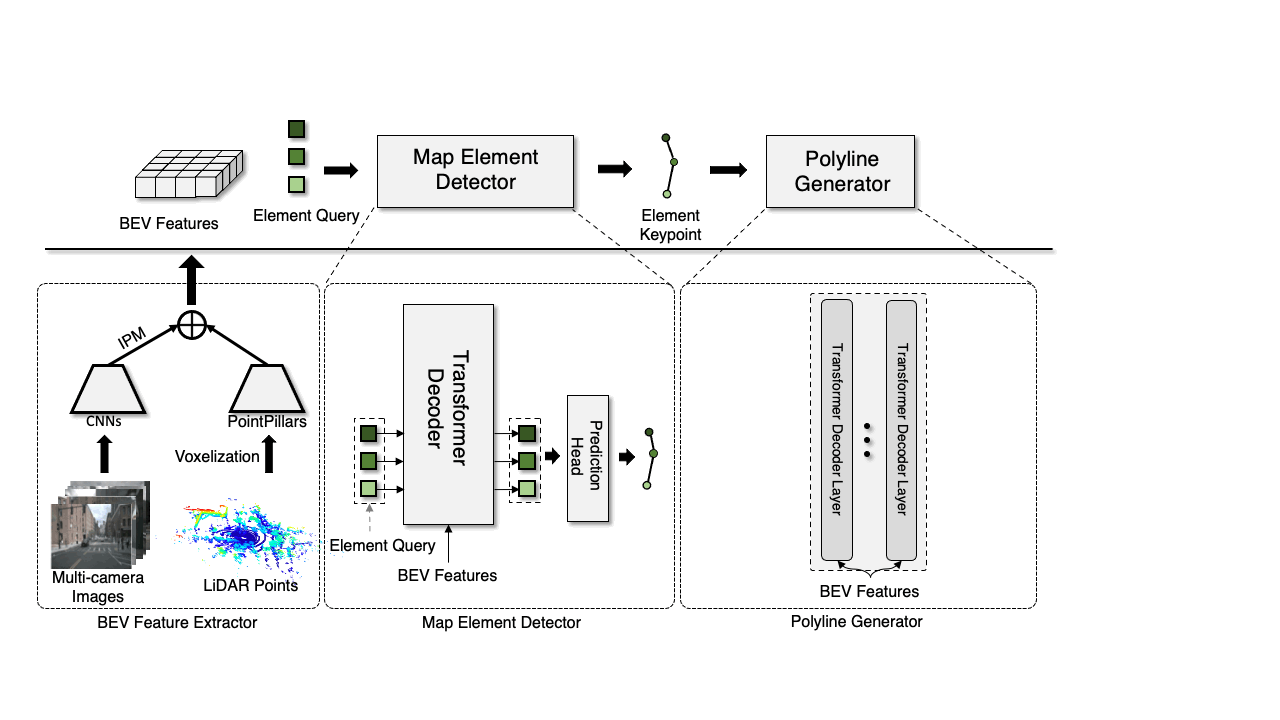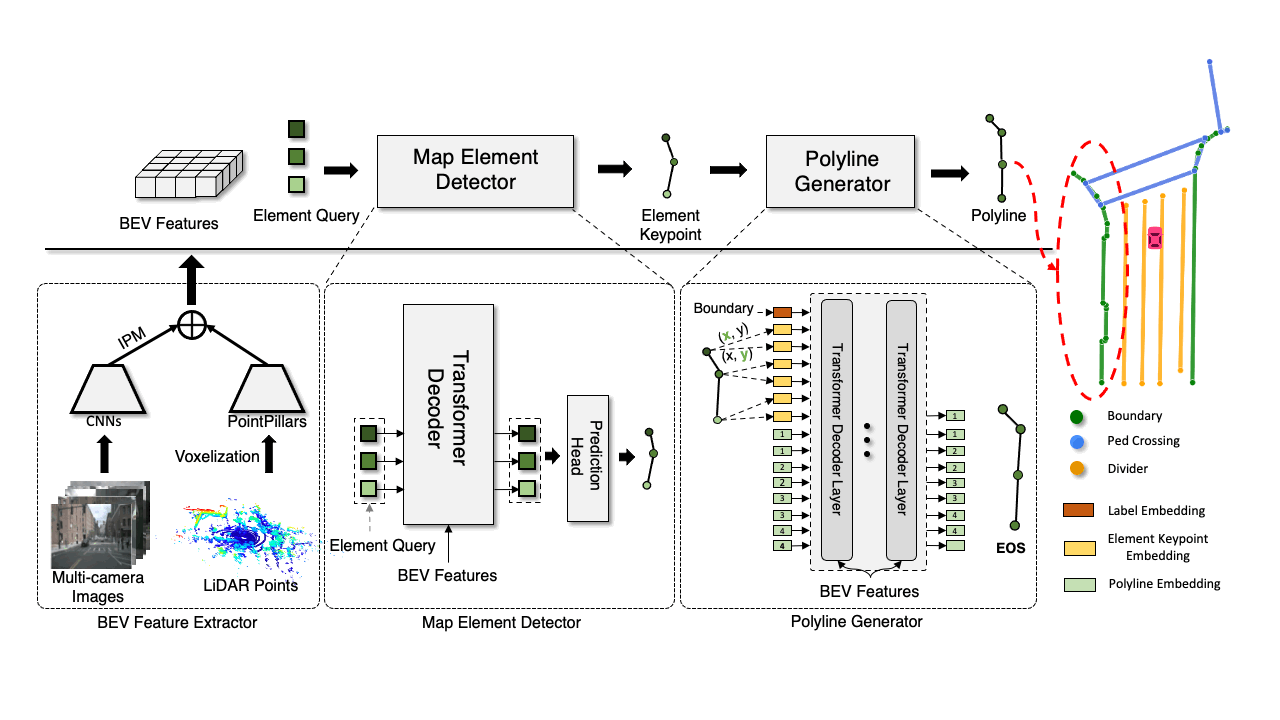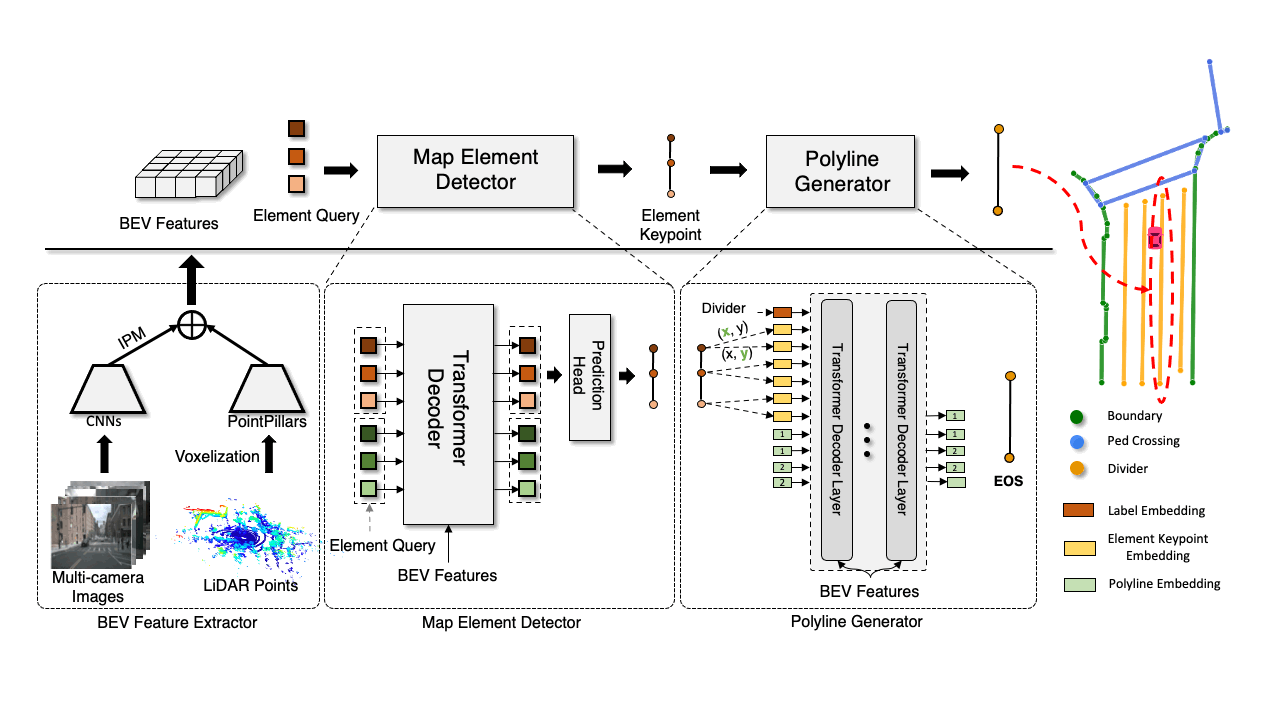
There are three key ingredients in our vectorized HD map generation pipeline, as shown in above figure.
A BEV feature extractor that map sensor data from sensor-view to a canonical BEV representation\(\mathcal{F}_{\mathrm{BEV}}\).
A scene-level map element detector that locates and classifies all map elements by predicting element keypoints \( \mathcal{A}=\{a_i\in\mathbb{R}^{k\times 2}|i=1,\dots,N\} \) and their class labels \( \mathcal{L} = \{l_i\in\mathbb{Z}|i=1,\dots,N\} \).
An object-level polyline generator that produces a polyline vertices sequence for each detected map element \((a_i, l_i)\).
Qualitative Results
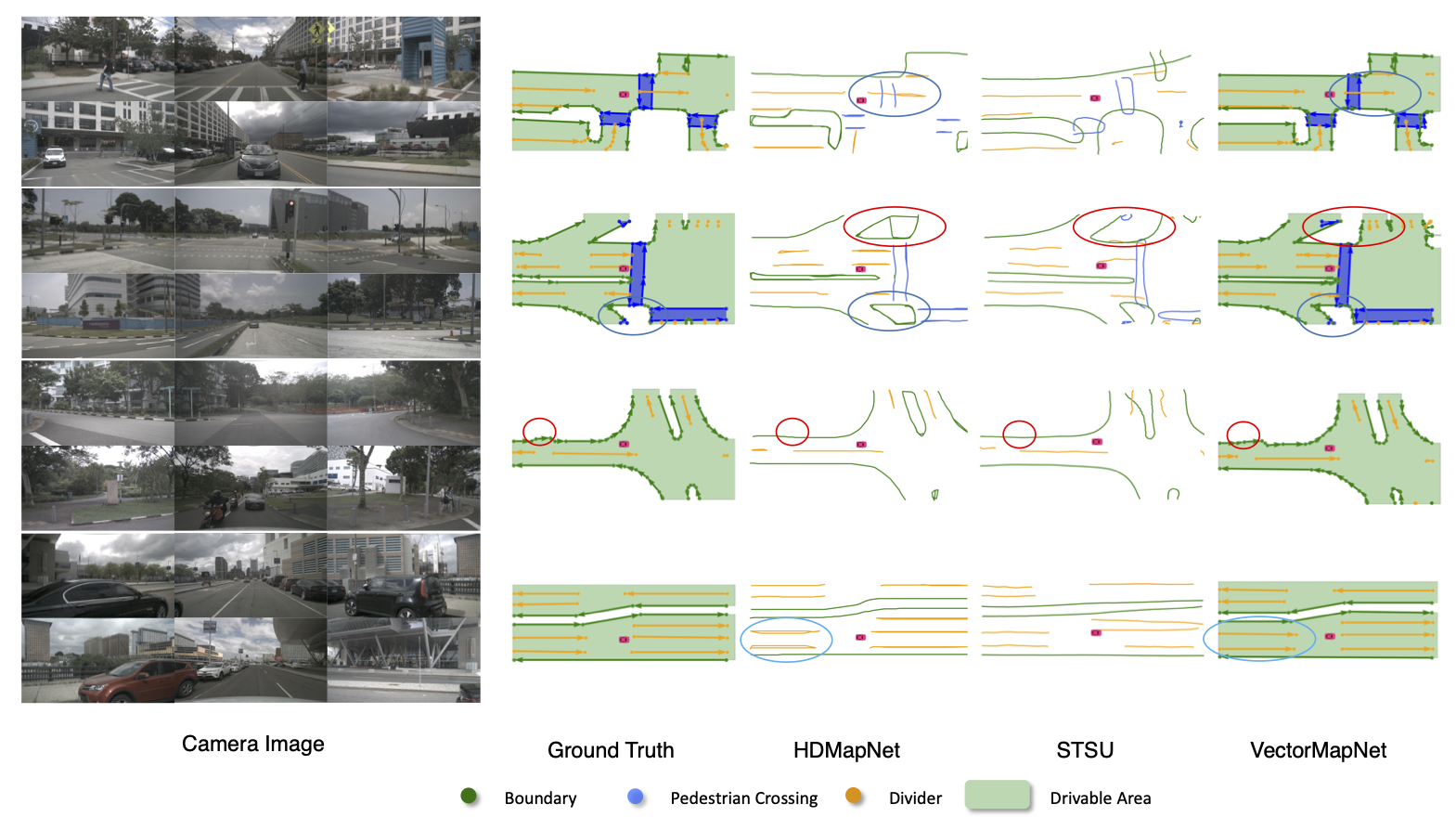
Qualitative results generated by VectorMapNet and baselines. We use camera images as inputs for comparisons. The areas enclosed by red and blue ellipses show that VectorMapNet can preserve sharp corners, and polyline representations prevent VectorMapNet from generating ambiguous self-looping results.
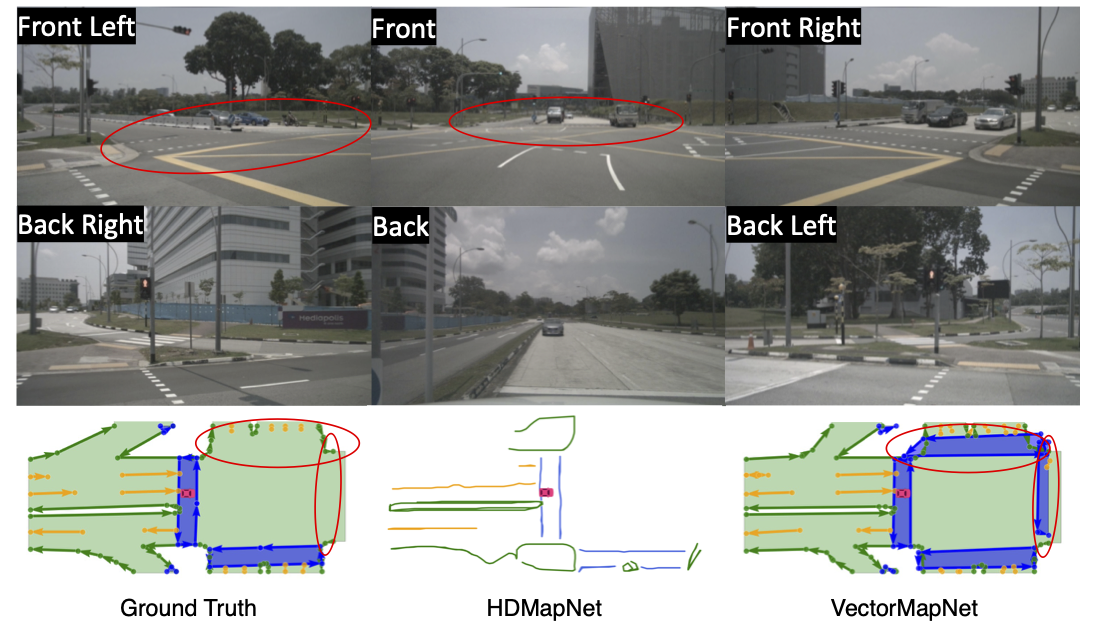
An example of VectorMapNet detecting unlabeled map elements. The red ellipse indicates a pedestrian crossing that is missing in ground truth annotations, while VectorMapNet detects it correctly. All the predictions are generated from camera images.
If you find our work useful in your research, please cite our paper:
@inproceedings{liu2022vectormapnet,
title={VectorMapNet: End-to-end Vectorized HD Map Learning},
author={Liu, Yicheng and Yuan, Tianyuan and Wang, Yue and Wang, Yilun and Zhao, Hang},
booktitle={International conference on machine learning},
year={2023},
organization={PMLR}
}